Audio processing is a rapidly advancing field within artificial intelligence where algorithms are designed to interpret and manipulate audio signals. From the early days of basic sound synthesis to today's voice assistants and automatic music generation, AI in audio processing has undergone significant development. Let's explore the history of this field and the key concepts and innovations that have shaped it.
A (not so) brief history of AI in audio processing
AI in audio processing began in the mid-20th century with work on sound synthesis methods. Max Mathews at Bell Labs in the 1950s laid the groundwork for digital audio synthesis.
In the late 1970s, the potential of AI in understanding and changing audio started to be explored. Early projects like the 'Talking Typewriter' by Kurzweil and Shrobe in 1978 demonstrated the possibilities of speech synthesis.
The 1990s saw the introduction of machine learning techniques like hidden Markov models (HMMs) for speech recognition. Rabiner's 1989 paper "A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition" was influential. HMMs had limitations, requiring substantial manual work and struggling with complex speech patterns.
The deep learning revolution
A major breakthrough in audio processing came with deep learning in the 2010s. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs), particularly Long Short-Term Memory (LSTM) networks, revolutionized speech recognition.
The 2014 paper "Deep Speech: Scaling up end-to-end speech recognition" by Hannun et al. showed the power of CNNs in learning from raw audio data, improving speech recognition performance. LSTMs, introduced by Hochreiter and Schmidhuber in 1997, proved effective in handling temporal dependencies in audio.
These techniques enhanced speech recognition and enabled audio generation. Models like WaveNet from DeepMind in 2016 generated lifelike speech and music by learning from large audio datasets.
Key concepts in modern audio processing
Fourier transforms and spectral analysis
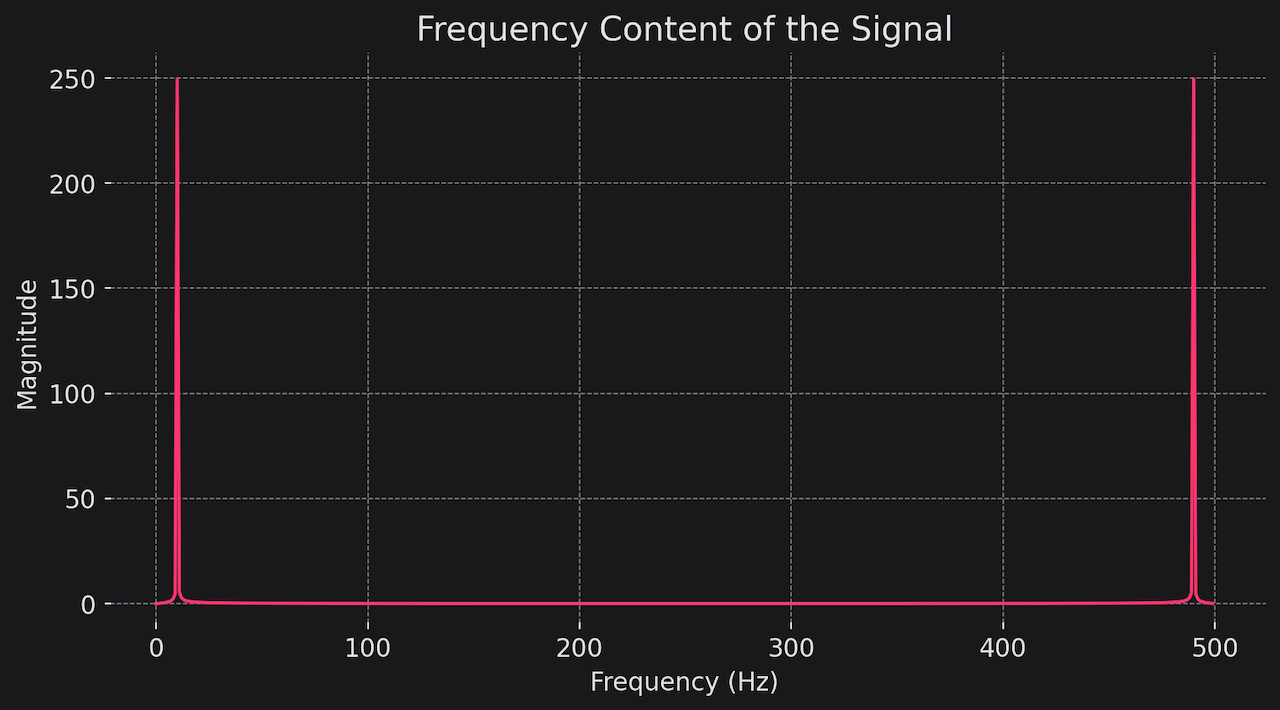
When you have a recording of a sound, it's a mix of many different frequencies (pitches) playing together. Fourier transforms are a way to separate these frequencies so you can see how much of each frequency is present in the sound.
This is useful because:
You can see which notes are being played by different instruments
You can remove frequencies you don't want, like noise or certain instruments
You can change the volume of specific frequencies to alter the balance of the sound
Here's a simple code example:
import numpy as np
# Make a simple sound wave
t = np.linspace(0, 1, 500)
f = 10 # Frequency in Hz
y = np.sin(2*np.pi*f*t)
# Apply Fourier transform
Y = np.fft.fft(y)
# Plot the frequency content
import matplotlib.pyplot as plt
plt.plot(np.abs(Y))
plt.show()
This code makes a simple sound wave, applies a Fourier transform to it, and plots the amount of each frequency present in the sound.
Deep neural networks
Deep neural networks (DNNs) are a way to make computers learn to recognize patterns in data, like recognizing different instruments in a piece of music. They work by passing the data through several layers that gradually pick out more and more complex features.
For example, to train a DNN to recognize musical instruments:
You give it many recordings of each instrument
The DNN learns patterns unique to each instrument
After training, the DNN can recognize the instrument in new recordings it hasn't heard before
Here's a simple DNN in code:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(500,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_data, train_labels, epochs=10, batch_size=32)
This code makes a simple DNN. It expects 500 input features (which could be the frequency content of a sound clip). It has two layers that process the data, and an output layer that predicts which of 10 possible instruments the sound is.
The model is trained on labeled data (recordings where we know what instrument is playing) using the fit() function. After training, it can predict the instrument for new recordings.
DNNs are useful in audio for things like:
Converting speech to text
Identifying the genre of a piece of music
Detecting emotions in speech
Removing background noise from recordings
The ability of DNNs to learn complex patterns makes them very useful for modern audio processing tasks.
Automatic speech recognition (ASR)
ASR systems convert spoken words into written text. They're incredibly useful for dictating messages, giving voice commands, or automatically transcribing meetings or lectures. ASR has improved dramatically thanks to deep learning, which allows these systems to learn patterns from vast amounts of speech data.
One of the best ASR systems is DeepSpeech, developed by Mozilla. It uses a deep neural network architecture called a recurrent neural network (RNN), which is particularly good at handling sequential data like speech. DeepSpeech 2, released in 2017, achieved a word error rate of just 5.5% on a standard benchmark, which was a significant milestone. Google's recent Conformer model has pushed the state of the art even further.
Sound generation and music composition
Generative AI models can create new sounds and music by learning patterns from existing audio data. This opens up exciting possibilities for music creation, sound design, and personalized audio content.
WaveNet, developed by DeepMind in 2016, was a breakthrough in audio generation. It can generate realistic speech and musical sounds by predicting the next sample in an audio waveform based on the samples that came before it. Google's Tacotron 2 built upon WaveNet to create high-quality synthetic speech that's nearly indistinguishable from human speech.
For music composition, OpenAI's MuseNet and Jukebox models are important developments. MuseNet can generate 4-minute musical compositions with 10 different instruments, while Jukebox can generate music in the style of popular genres and artists. These models demonstrate the potential for AI to be a powerful tool for musicians and composers.
Get started with audio processing in Appwrite
Appwrite provides a platform to build your own audio processing applications. With our AI function templates and tutorials, you can quickly get started with voice recognition, music generation, and more.