Integrate any database type into your Appwrite project
Databases allow you to store and query your application’s information persistently. Storing is usually straightforward, but querying data optimally is a major challenge for applications at any scale. Instead of simply saying it depends, we have prepared a list of Cloud database providers, explained their unique features, and shared examples where they shine. For each database, we also provide an Appwrite Function that allows you to integrate the database into your Appwrite project.
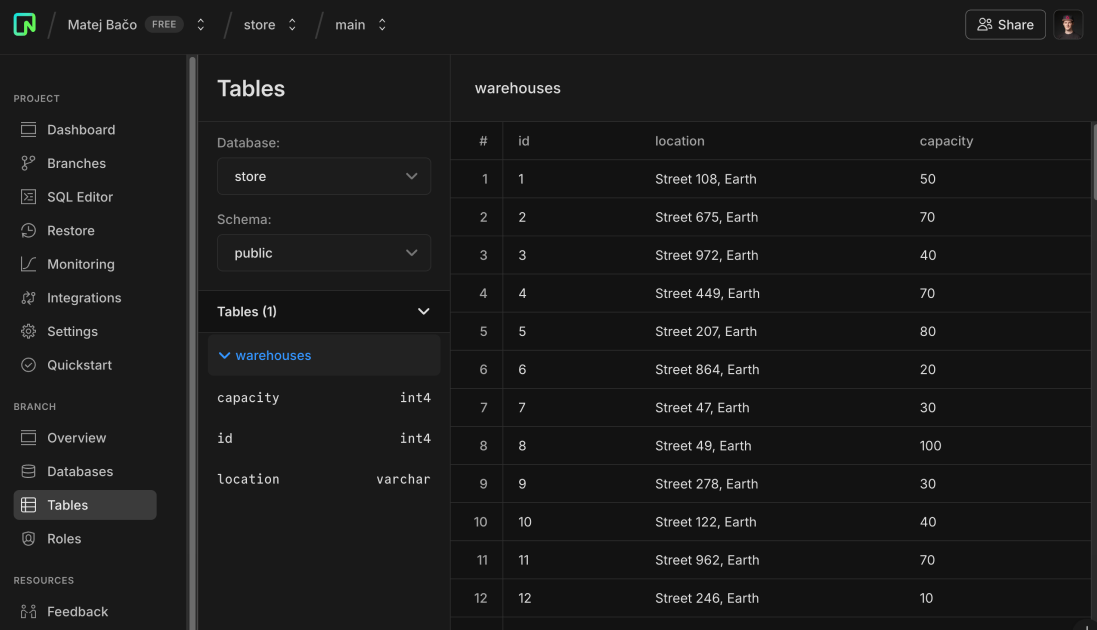
Appwrite Database
Most applications don’t include complex database logic, at least not at the beginning. Typically, applications start with basic features that bring value to some customers and gradually improve their features to provide value to a wider range of users.
For such database needs, you can use Appwrite Database directly. It comes included in your Appwrite project, so no additional setup is needed to connect to it. Appwrite Databases include the most commonly needed database features such as filtering, sorting, pagination, and more. It’s best to use Appwrite Databases as your main database for an Appwrite project since it’s inside Appwrite’s ecosystem and easily integrates with Appwrite Auth permissions.
For more specific use cases, different databases may offer more features and better performance. For example, a search query in the Appwrite Database is perfect for a search input, but if primary feature of your product is searching, you could look for a robust search engine. Database with dedication towards searching could offer mistake tolerance, synonym awareness, or result personalization.
Alternatively, you might be building a project on top of data you already have in an external database. Your team may be very experienced with self-hosting a database, or your client may require the use of a specific database. There are wide variety of reasons why a separate database might be a right choice for your project. We are well aware of those situations, and Appwrite was built with that in mind. It’s deeply embedded in our philosophy to meet developers where they are and allow them to work with any tools or technologies that they need and love.
Neon - Serverless Postgres
Neon provides a managed Postgres database, which is famously known for its SQL syntax and ability to store structured data.
For most databases, it’s beneficial for data to be structured. Structure gives data predictability and reliability, which is key to any production-ready application.
SQL databases are also preferred when relations between data play a big role in preventing data duplication and ease of updating the data in one place. Postgres specifically allows you to add extensions to store and query geospatial and vector data efficiently.
To integrate with Neon, you can set up an Appwrite function and prepare a Postgres client.
import postgres from 'postgres';
let client;
export default async ({ req, res, log, error }) => {
// Connect to database
if(!client) {
const { PGHOST, PGDATABASE, PGUSER, PGPASSWORD, ENDPOINT_ID } = process.env;
client = postgres({
host: PGHOST,
database: PGDATABASE,
username: PGUSER,
password: PGPASSWORD,
port: 5432,
ssl: 'require',
connection: {
options: `project=${ENDPOINT_ID}`,
},
});
}
// Rest of the code
};
Next, you can run SQL queries to create a table, insert data, read it, and much more.
// Prepare table
await client`CREATE TABLE IF NOT EXISTS warehouses (
id SERIAL PRIMARY KEY,
location VARCHAR(255),
capacity INT
)`;
// Insert data
const location = `Street ${Math.round(Math.random() * 1000)}, Earth`; // Random address
const capacity = 10 + Math.round(Math.random() * 10) * 10; // Random number: 10,20,30,...,90,100
await client`INSERT INTO warehouses (location, capacity) VALUES (${location}, ${capacity})`;
// Query data
const page = 1;
const limit = 100;
const warehouses = await client`SELECT * FROM warehouses LIMIT ${limit} OFFSET ${(page - 1) * limit}`;
return res.json(warehouses);
You can find an entire example in our query Neon Postgres function template, which is also available on your Appwrite Console in the Functions Marketplace.
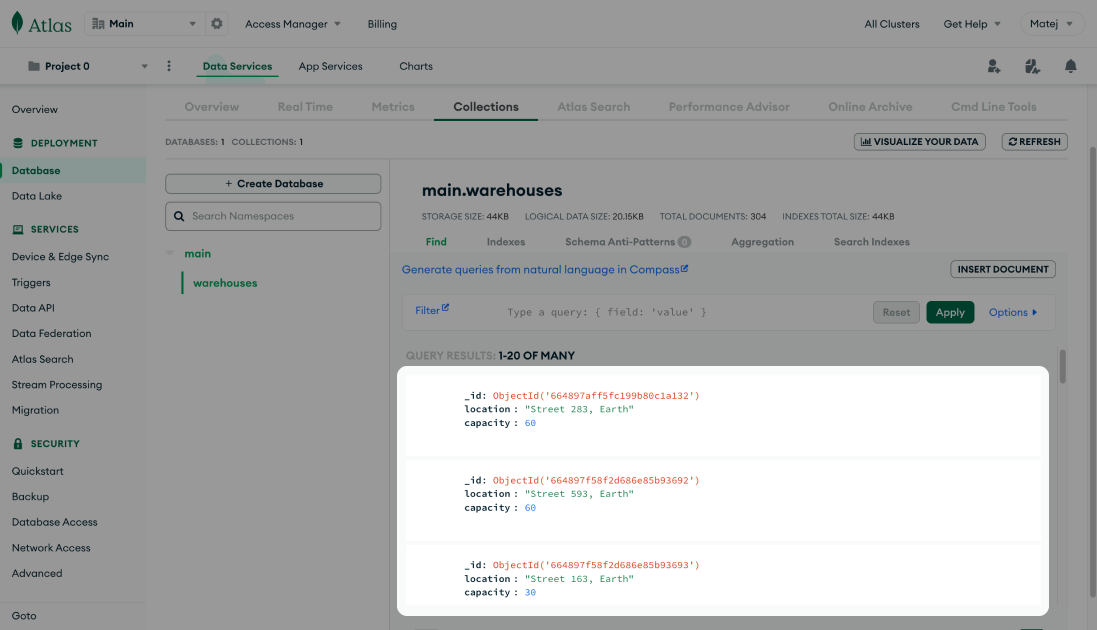
MongoDB Atlas
Atlas, a managed cloud platform by the MongoDB team, is a cloud provider of MongoDB clusters.
MongoDB database is well-known for its JSON document structure. This approach allows you to store unstructured data optimally, with a huge improvement boost to write operations. For instance, usage stats or sales history could be stored in MongoDB and later processed to gain more insights into app analytics.
While MongoDB shines the most in storing unstructured data, nowadays, it provides all the capabilities developers expect from a relational database. If you don’t like SQL queries, MongoDB is a great choice.
With MongoDB, integration becomes simpler, since you don’t need to define structure of collections or documents. After preparing a client, you can directly start writing and querying data.
import { MongoClient, ServerApiVersion } from 'mongodb';
let client;
export default async ({ req, res, log, error }) => {
// Connect to database
if(!client) {
client = new MongoClient(process.env.MONGO_URI, {
serverApi: {
version: ServerApiVersion.v1,
strict: true,
deprecationErrors: true,
}
});
await client.connect();
}
// Insert data
const location = `Street ${Math.round(Math.random() * 1000)}, Earth`; // Random address
const capacity = 10 + Math.round(Math.random() * 10) * 10; // Random number: 10,20,30,...,90,100
await client.db("main").collection("warehouses").insertOne({
location,
capacity
});
// Query data
const page = 1;
const limit = 100;
const cursor = client.db("main").collection("warehouses")
.find().limit(limit).skip((page - 1) * limit);
const docs = [];
for await (const doc of cursor) {
docs.push(doc);
}
return res.json(docs);
};
A better-structured example can be found in the query Mongo Atlas function template and also on your Appwrite Console.
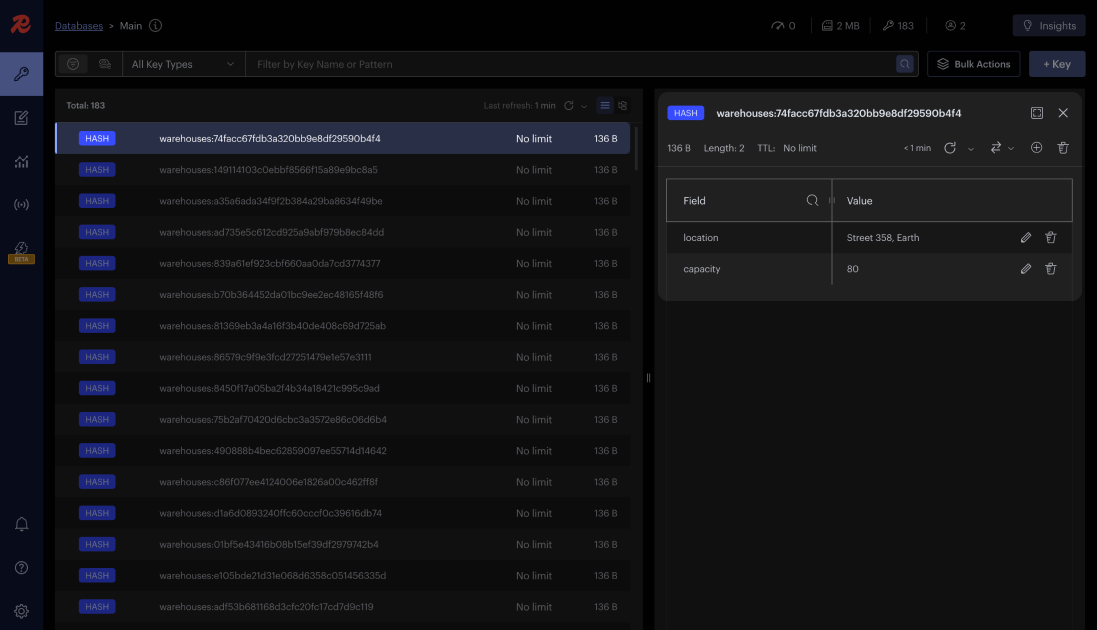
Redis
Redis is a widely used key-value database, most often serving as a cache layer in front of another database. It’s faster than the underlying database since Redis stores data in memory.
While the cache is a typical use case for Redis, it can be used for much more since it can also store data persistently to disk. Its key-value approach renders very fast read and write operations, with the latest Redis version also supporting querying capabilities. Other use cases for Redis include pub/sub, atomic counters, distributed locks, and message queues.
You can start integrating with Redis by creating and connecting a client.
import { createClient } from 'redis';
import { createHash } from 'node:crypto';
let client;
export default async ({ req, res, log, error }) => {
// Connect to database
if(!client) {
const { REDIS_PASSWORD, REDIS_HOST } = process.env;
client = createClient({
password: REDIS_PASSWORD,
socket: {
host: REDIS_HOST,
port: 14714
}
});
await client.connect();
}
// Rest of the code
};
Next, you can start inserting data. Since Redis is a key-value store, we need to create a unique key for every value. In the example below, an MD5 hash is used because the MD5 hash of the query is what’s commonly used as a key.
// Insert data
const location = `Street ${Math.round(Math.random() * 1000)}, Earth`; // Random address
const capacity = 10 + Math.round(Math.random() * 10) * 10; // Random number: 10,20,30,...,90,100
const hash = createHash('md5').update(location).digest('hex');
await client.hSet(`warehouses:${hash}`, {
location,
capacity
});
Querying data is as simple as fetching it using the key (MD5 hash). Many more operations are supported, such as JSON or array manipulation, but for simplicity, you can read a value by a key.
// Query data
const warehouses = await client.hGetAll(`warehouses:${hash}`);
return res.json(warehouses);
A working example can be found in our query Redis Labs function template or in your Appwrite Console.
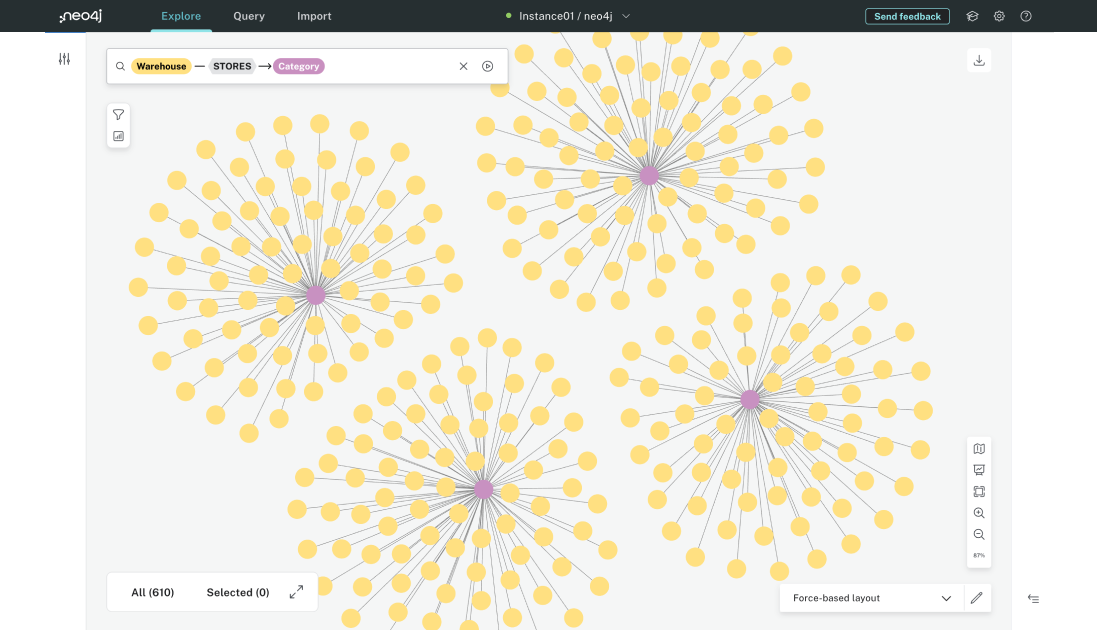
Neo4j AuraDB
AuraDB is a cloud offering of Neo4j, the leading graph database. Using Cypher, a graph query language, Neo4j allows you to store data with attention to their relations. Non-relational data can live in the Neo4j database but it’s a very rare use case.
Usually, every node is connected to another node, creating a large net of relations. Graph database gives benefits similar to relational databases, but to a much larger extent.
Compared to databases like Postgres, Neo4j is much more focused on relations and encourages a large chain of relations. With relations between all data, features such as recommendation feed or friend discoverability become effortless.
To use Neo4j with Appwrite Functions, you can create a function and connect using the Neo4j driver.
import { driver, auth, int } from 'neo4j-driver';
let client;
export default async ({ req, res, log, error }) => {
// // Connect to database
if(!client) {
const { NEO4J_URI, NEO4J_USER, NEO4J_PASSWORD } = process.env;
client = driver(NEO4J_URI, auth.basic(NEO4J_USER, NEO4J_PASSWORD))
}
// Rest of the code
}
Next, you can insert data as nodes with relations between them. You can use MERGE clause to ensure a node is re-used instead of creating duplicates.
// Insert data
const categories = [ 'electronics', 'fashion', 'furniture', 'cars' ];
const category = categories[Math.floor(Math.random() * categories.length)]; // Random category
const location = `Street ${Math.round(Math.random() * 1000)}, Earth`; // Random address
const capacity = 10 + Math.round(Math.random() * 10) * 10; // Random number: 10,20,30,...,90,100
await client.executeQuery(
`
MERGE (c:Category {name: $category})
CREATE (w:Warehouse {location: $location, capacity: $capacity})
CREATE (w)-[:STORES]->(c)
`,
{ location, capacity, category },
{ database: 'neo4j' }
);
Finally, you can view your data using RETURN clause in a query.
// Query data
const page = 1;
const limit = 100;
const offset = (page - 1) * limit;
const graph = await client.executeQuery(
`
MATCH (w:Warehouse)-[:STORES]->(c:Category)
RETURN w, c
SKIP $offset
LIMIT $limit
`,
{ limit: int(limit), offset: int(offset) },
{ database: 'neo4j' }
);
return res.json(graph);
You can look at the entire example put together in the query Neo4j AuraDB template or in your Functions Marketplace in Appwrite Console.
Upstash Vector
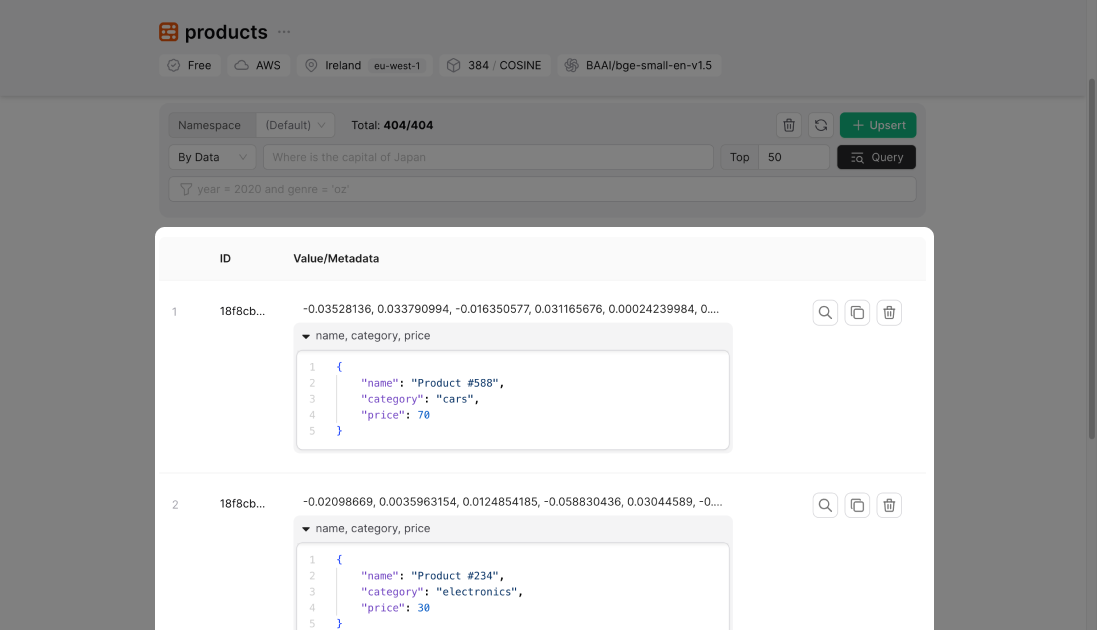
Upstash is a data platform that offers services such as Redis, Kafka, or QStash, but most importantly, a vector database. Vector database stores multi-dimensional numeric representations of your data (embeddings) in an index, allowing you to find similarities between them quickly.
There are AI models to generate embeddings from text, music, or images, which is the main purpose of vector databases. Using a AI model such as a large language model (LLM), you could create a vector database of your product names. Later, a visitor may be looking for a flower pot, but thanks to the vector database, your website can now recommend watering cans and fertilizer.
Integrating with Upstash Vector is unbelievably simple. Usually, you would have to connect to an AI model yourself to generate embeddings. In latest Upstash, you can pick model when creating an index, and the embedding is created for you automatically, for any input you provide. With that in mind, you can create an Appwrite Function that connects to Upstash, and inserts your data.
import { Index } from "@upstash/vector"
let client;
export default async ({ req, res, log, error }) => {
// Connect to database
if(!client) {
const { UPSTASH_URL, UPSTASH_TOKEN } = process.env;
client = new Index({ url: UPSTASH_URL, token: UPSTASH_TOKEN });
}
// Insert data
const categories = ['electronics', 'fashion', 'furniture', 'cars'];
const category = categories[Math.floor(Math.random() * categories.length)]; // Random category
const name = `Product #${Math.round(Math.random() * 1000)}`; // Random name
const price = 10 + Math.round(Math.random() * 90); // Random number between 10 and 100
const id = `${new Date().getTime().toString(16)}${Math.round(Math.random() * 1000000000).toString(16)}`; // Unique ID
await client.upsert({
id,
data: `product name ${name} in category ${category} priced at ${price}€`,
metadata: { name, category, price },
});
// Rest of the code
}
After inserting data, Upstash takes a few seconds to generate embeddings and store it in the database. Once the index is ready, you can query your database and look for similar products.
const embedding = await client.query({
data: "product name Airpods in category electronics priced at 36€",
topK: 1,
includeVectors: true,
includeMetadata: true,
});
return res.json(embedding);
If needed for your use-case, you can disable automatic embedding generation from Upstash, and use any AI model of your choice. You can use the query Upstash Vector Appwrite Function template as a reference for your implementation. Additionally, you can find this example in Appwrite Console when setting up a new function.
Next steps
Your database journey doesn’t end here. There are other databases you might already love, or look forward to trying in your next project. Thanks to nature of Appwrite Functions, your imagination is the limit. We look forward showcasing more databases and how you can integrate them with Appwrite.
If you want to share your favorite database with us, or need help integrating with your database, I invite you to Join our Discord community.
Lastly, if you are feeling inspired, you can contribute to templates you have read about. In our Appwrite Functions templates repository, we implemented integrations in Node.JS, but developers use a dozen other languages. We would love to see issues and pull requests converting the function into other languages.