Hugging Face is a platform that hosts ML models for all types of applications, including for speech recognition. This example uses the openai/whisper-large-v3 from Hugging Face to perform speech recognition.
Prerequisites
An Appwrite project
Create new function
Head to the Appwrite Console then click on Functions in the left sidebar and then click on the Create Function button.
In the Appwrite Console's sidebar, click Functions.
Click Create function.
Under Connect Git repository, select your provider.
After connecting to GitHub, under Quick start, select the Node.js starter template.
In the Variables step, add the HUGGINGFACE_ACCESS_TOKEN, generate it here.
Follow the step-by-step wizard and create the function.
Add dependencies
Once the function is created, clone the function and open it in your development environment.
Install the Hugging Face SDK and the Appwrite Node.js SDK so we can upload the generated audio file to Appwrite Storage.
npm install @huggingface/inference node-appwrite
Create an Appwrite service
The function will interact with Appwrite to store the original audio and generated text transcript. To make this easier, create a service class that will handle all the Appwrite interactions.
Create a file called src/appwrite.js and implement the following class:
import { Client, Databases, ID, Storage } from 'node-appwrite';
class AppwriteService {
constructor() {
const client = new Client();
client
.setEndpoint(
process.env.APPWRITE_ENDPOINT ?? 'https://cloud.appwrite.io/v1'
)
.setProject(process.env.APPWRITE_FUNCTION_PROJECT_ID)
.setKey(process.env.APPWRITE_API_KEY);
this.databases = new Databases(client);
this.storage = new Storage(client);
}
async createRecognitionEntry(databaseId, collectionId, audioId, speech) {
await this.databases.createDocument(
databaseId,
collectionId,
ID.unique(),
{
audio: audioId,
speech: speech,
}
);
}
async getFile(bucketId, fileId) {
return await this.storage.getFileDownload(bucketId, fileId);
}
}
export default AppwriteService;
The constructor initializes the Appwrite client and the database and storage services. This createRecognitionEntry method creates a document in the Appwrite database with the audio and speech recognition text. This getFile method retrieves a file from Appwrite Storage.
Create Storage bucket
In order for this function to work, create a new bucket in the Appwrite Storage. You can do this by navigating to the Appwrite Console and clicking on Storage in the left sidebar, then clicking on the Create Bucket button.
Use the default configuration for the bucket. Make sure to note down the bucket ID so you can add it as an environment variable later.
Create Appwrite collection
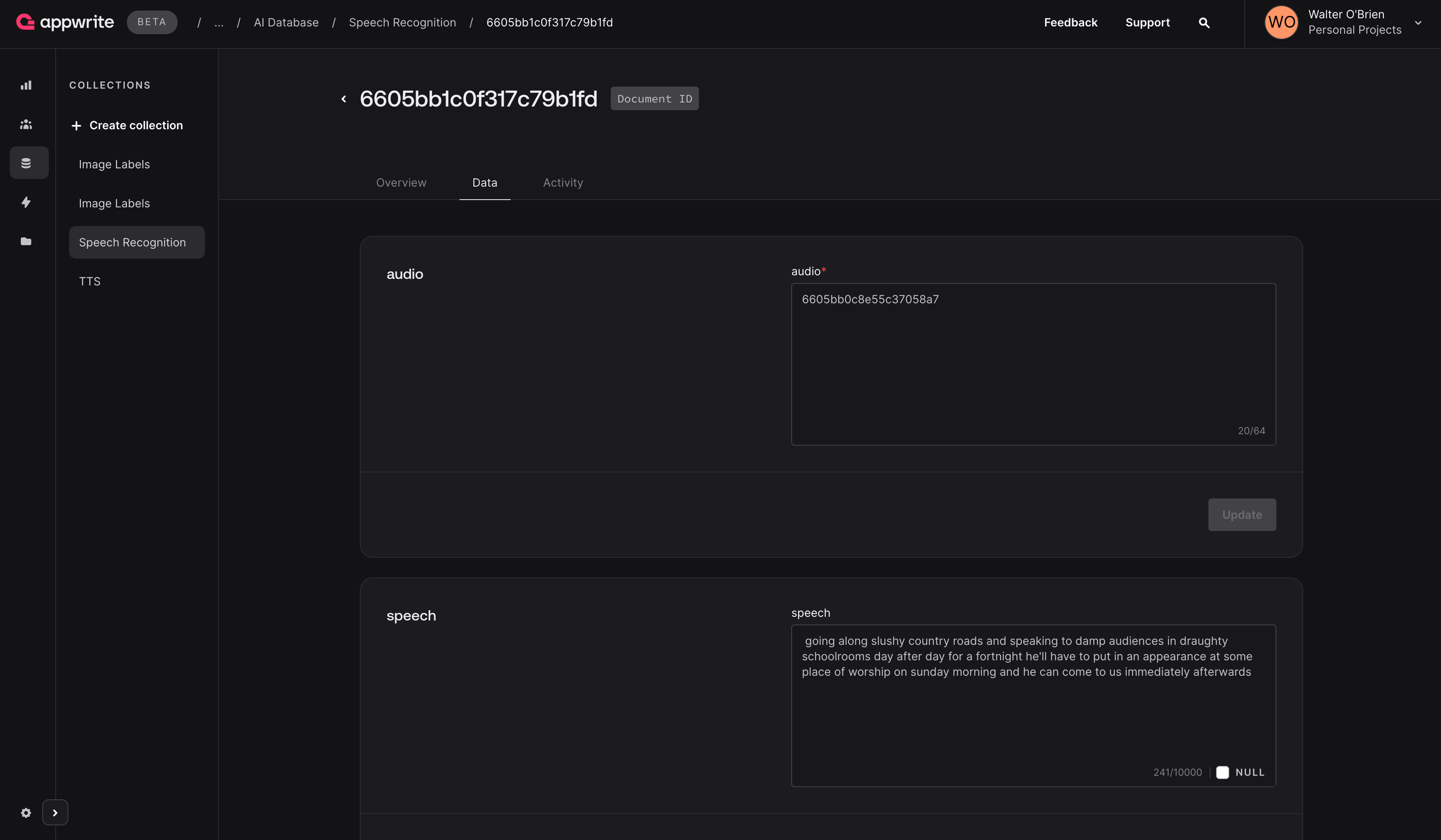
Before saving the classification result to Appwrite Databases, create a new database and collection in the Appwrite Console.
Navigate to the Appwrite Console and click on Database in the left sidebar, then click on the Create database button, and name it, for example AI. Once you've created the database, click on the Create collection button and create a new collection, and name it, for example Speech Recognition.
Next, create the following schema for the collection:
| Attribute | Type | Size | Required | Array |
| audio | String | 64 | true | false |
| speech | String | 10000 | true | false |
Integrate with Hugging Face
In src/main.js implement the following function to convert speech to a text transcript using the Hugging Face API.
import { HfInference } from '@huggingface/inference';
import AppwriteService from './appwrite.js';
export default async ({ req, res, log, error }) => {
const databaseId = process.env.APPWRITE_DATABASE_ID ?? 'ai';
const collectionId = process.env.APPWRITE_COLLECTION_ID ?? 'speech_recognition';
const bucketId = process.env.APPWRITE_BUCKET_ID ?? 'speech_recognition';
let fileId = req.body.$id || req.body.fileId;
if (!fileId) {
return res.send('Bad request', 400);
}
if (
req.body.bucketId &&
req.body.bucketId != bucketId
) {
return res.send('Bad request', 400);
}
const appwrite = new AppwriteService();
const file = await appwrite.getFile(bucketId, fileId);
const hf = new HfInference(process.env.HUGGING_FACE_API_KEY);
const result = await hf.automaticSpeechRecognition({
data: file,
model: 'openai/whisper-large-v3',
});
await appwrite.createRecognitionEntry(databaseId, collectionId, fileId, result.text);
log('Audio ' + fileId + ' recognised', result.text);
return res.json({ text: result.text });
};
This Appwrite Function checks if the required environment variables are set, then load the original audio from Appwrite Storage. The function processes the audio file using the Hugging Face API, stores the generated text transcript in Appwrite Databases and returns the transcript text.
Test the function
Test our function by uploading an audio file the Appwrite Storage.
Navigate to the Appwrite Console and click on Storage in the left sidebar, then click on the Upload File button and upload an image. After a few seconds, you should see an execution appear in the function's execution logs and the classification result should be saved to the Appwrite Database.